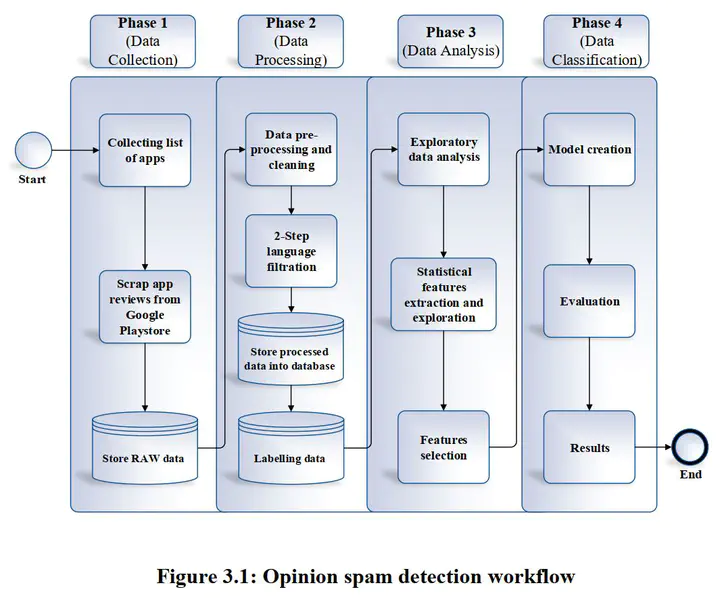
Product reviews are the individual’s opinions, judgement or belief about a certain product or service provided by certain companies. Such reviews serve as guides for these companies to plan and monitor their business ventures in terms of increasing productivity or enhancing their product/service qualities. There are free and paid products or services provided by companies and most of the time, they are full of past customers’ reviews. Before purchasing a product or services, customers often read the reviews about the product before making any decision whether to purchase the product. These reviews help to increase business profits by convincing future customers about the products. In the mobile application marketplace such as Google Play store, reviews and star ratings are used as indicators of the application quality. Similarly, Yelp serves as a popular reviews and recommendation website for top restaurants, hotels, services, shopping and entertainment as the measurement for the service quality. However, among all these reviews and opinions, spams also exist, to disrupt the online business balance. Previous studies used the time series and neural network approach which require a lot of computational time to detect these opinion spams. However, the detection performance can be restricted in terms of accuracy because the approach focusses on basic, discrete and document level features only thereby, projecting little statistical relationships. Aiming to improve the opinion spams detection effectiveness in mobile application marketplaces, this study proposes additional statistical-based features, together with the existing features proposed by previous studies. Since there are few known works that implements boosting models in detecting opinion spams, this study introduces boosting application into opinion spam detection through two major boosting systems which are Extreme Gradient Boosting (XGBoost) and Generalized Boosted Regression Model (GBM). To evaluate the boosting application models, this study distinguishes the Malayiv language dataset (Google Play store) as the private dataset and the English language dataset (Yelp) as the public dataset. To demonstrate the evaluation performance of the developed model, seven benchmark metrics (i.e. accuracy, True Positive Rate (TPR), False Positive Rate (FPR), specificity, precision, F-measure and AUC) were applied. The results of this study show that the additional statistical-based features and the application of boosting models facilitate in improving the effectiveness of opinion spams detection. The main contribution of this study is to have selected, proposed and evaluate a model that uses statistical-based features and the application of boosting models in detecting opinion spams on multilingual datasets.